| .github/workflows | ||
| .reuse | ||
| .vscode | ||
| backend | ||
| frontend | ||
| gephi | ||
| LICENSES | ||
| .dokku-monorepo | ||
| .gitignore | ||
| .gitlab-ci.yml | ||
| BILL-OF-MATERIALS.md | ||
| CHANGELOG.md | ||
| example.env | ||
| LICENSE | ||
| netlify.toml | ||
| nlnet-logo.png | ||
| README.md | ||
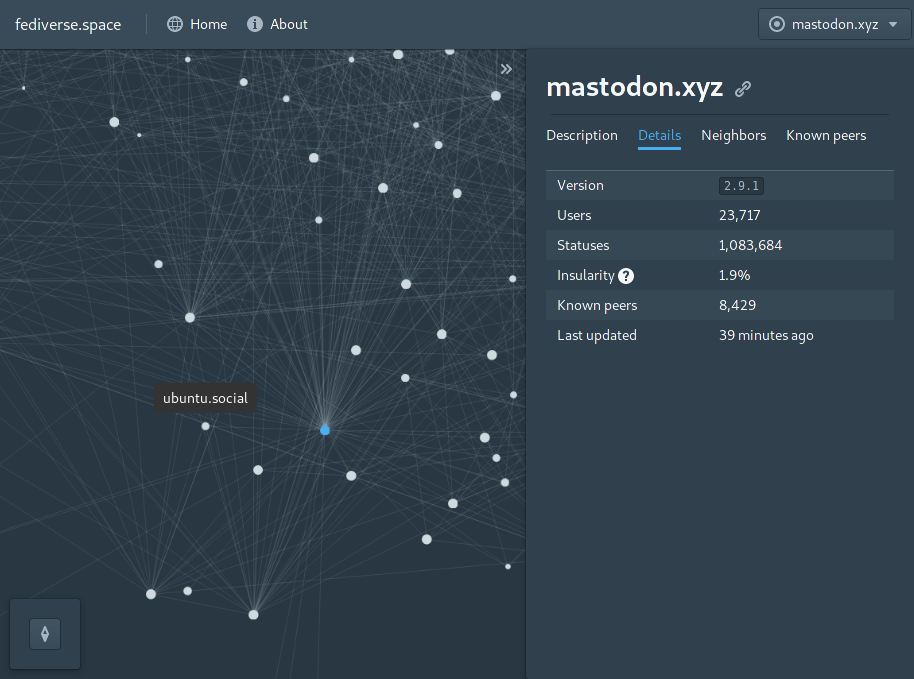
| screenshot.png | ||
{kind=link}
{kind=link}
index.community 🌐
The map of the fediverse that you always wanted.
Read the latest updates on Mastodon: @indexCommunity
Requirements
Note: examples here use podman. In most cases you should be able to replace podman with docker.
Though containerized, backend development is easiest if you have the following installed.
- For the crawler + API:
- Elixir
- Postgres
- For laying out the graph:
- Java
- For the frontend:
- Node.js
- Yarn
Running it
Backend
cp example.env .envand modify environment variables as requiredpodman build gephi && podman build phoenixpodman run --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:6.8.9- If you've
runthis container previously, usepodman start elasticsearch
- If you've
podman run --name postgres -e "POSTGRES_USER=postgres" -e "POSTGRES_PASSWORD=postgres" -p 5432:5432 postgres:12podman-compose -f compose.backend-services.yml -f compose.phoenix.yml- Create the elasticsearch index:
iex -S mix app.startElasticsearch.Index.hot_swap(Backend.Elasticsearch.Cluster, :instances)
Frontend
cd frontend && yarn installyarn start
Commands
Backend
./gradlew shadowJar compiles the graph layout program. java -Xmx1g -jar build/libs/graphBuilder.jar runs it.
Frontend
yarn buildcreates an optimized build for deployment
Privacy
This project doesn't crawl personal instances: the goal is to understand communities, not individuals. The threshold for what makes an instance "personal" is defined in the backend config and the graph builder SQL.
Deployment
You don't have to follow these instructions, but it's one way to set up a continuous deployment pipeline. The following are for the backend; the frontend is just a static HTML/JS site that can be deployed anywhere.
- Install Dokku on your web server.
- Install dokku-postgres, dokku-monorepo, dokku-elasticsearch, and dokku-letsencrypt.
- Create the apps
dokku apps:create phoenixdokku apps:create gephi
- Create the backing database
dokku postgres:create fediversedbdokku postgres:link fediversedb phoenixdokku postgres:link fediversedb gephi
- Set up ElasticSearch
dokku elasticsearch:create fediversedokku elasticsearch:link fediverse phoenix
- Update the backend configuration. In particular, change the
user_agentin config.exs to something descriptive. - Push the apps, e.g.
git push dokku@<DOMAIN>:phoenix(note that the first push cannot be from the CD pipeline). - Set up SSL for the Phoenix app
dokku letsencrypt phoenixdokku letsencrypt:cron-job --add
- Set up a cron job for the graph layout (use the
dokkuuser). E.g.
SHELL=/bin/bash
0 2 * * * /usr/bin/dokku run gephi java -Xmx1g -jar build/libs/graphBuilder.jar
Before the app starts running, make sure that the Elasticsearch index exists -- otherwise it'll create one called
instances, which should be the name of the alias. Then it won't be able to hot swap if you reindex in the future.
Acknowledgements
![]()
Many thanks to NLnet for their support and guidance of this project.